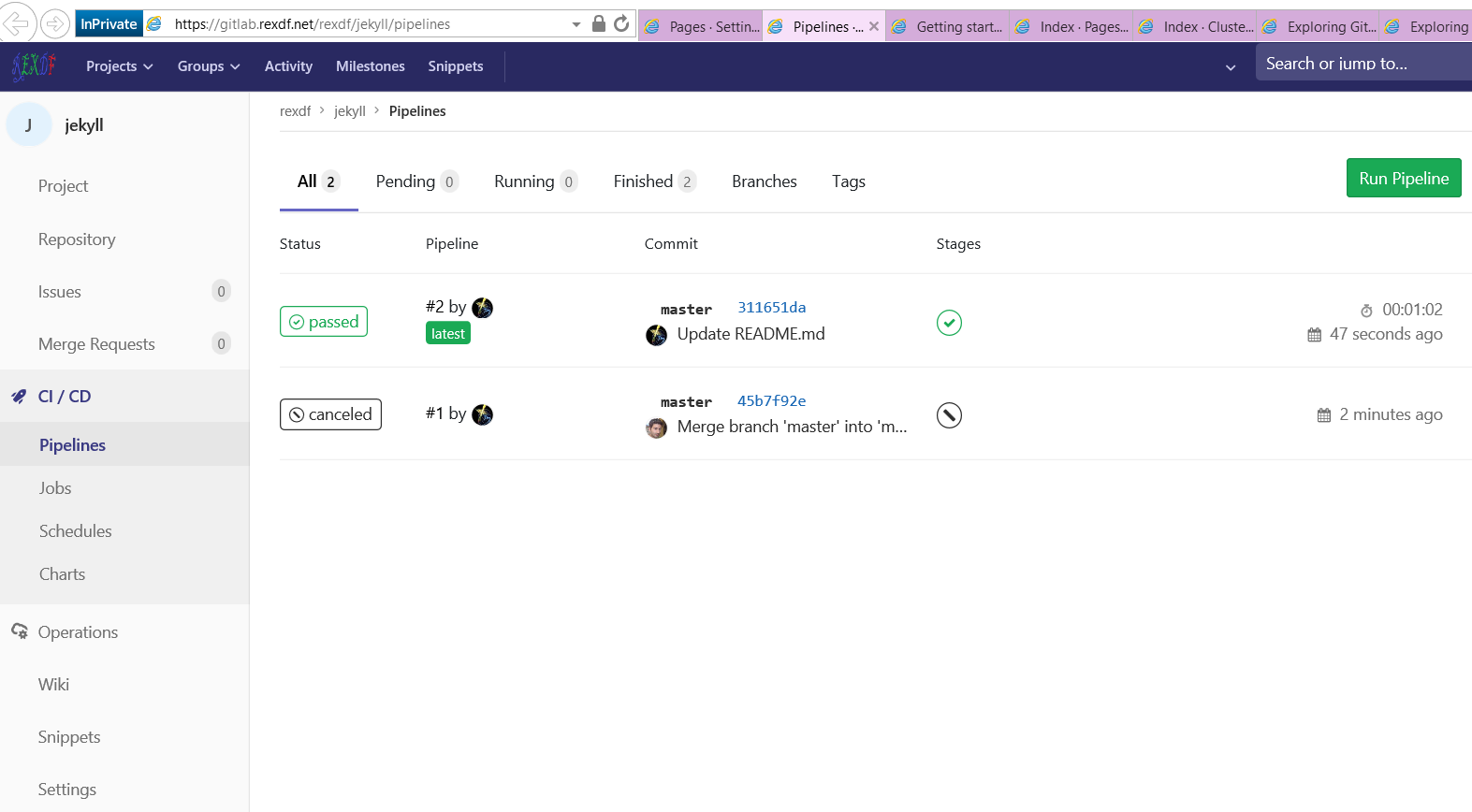
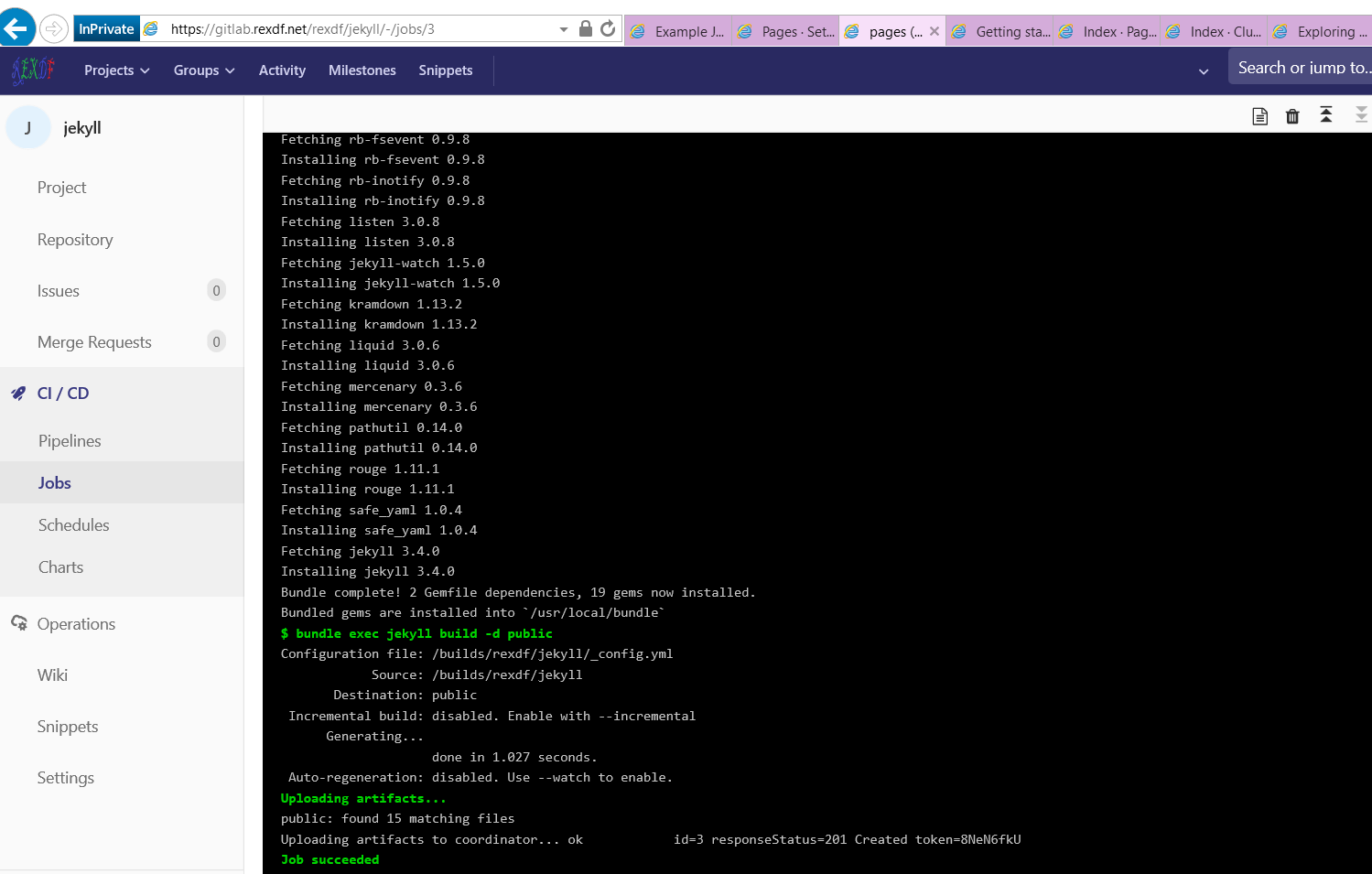
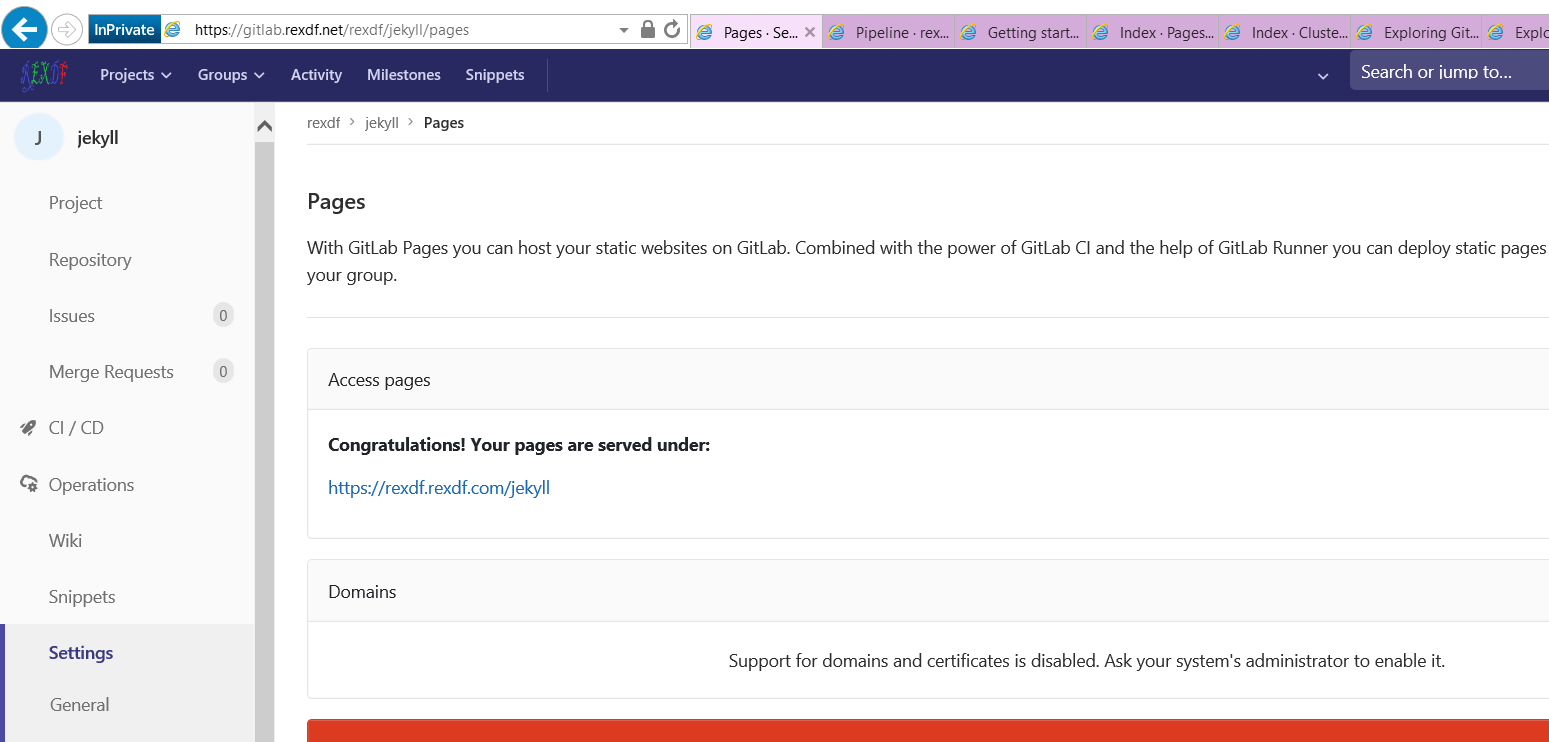
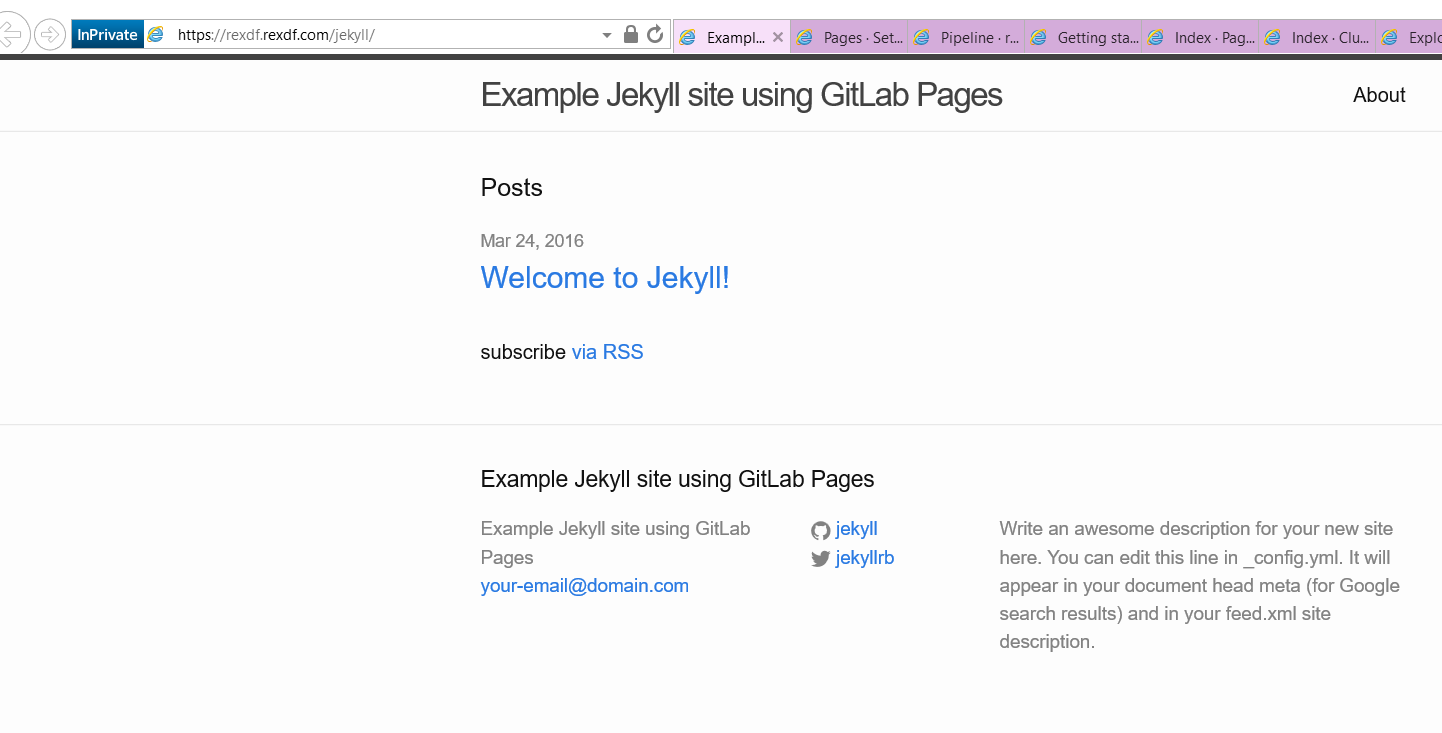
diff -r a5e1a8813a3f src/GvimExt/gvimext.cpp
--- a/src/GvimExt/gvimext.cpp Thu Jun 25 18:36:26 2015 +0200
+++ b/src/GvimExt/gvimext.cpp Fri Jun 26 01:26:10 2015 +0800
@@ -157,7 +157,7 @@
# define _(x) (*dyn_libintl_gettext)(x)
# define VIMPACKAGE "vim"
# ifndef GETTEXT_DLL
-# define GETTEXT_DLL "libintl.dll"
+# define GETTEXT_DLL "intl.dll"
# endif
// Dummy functions
diff -r a5e1a8813a3f src/Make_mvc.mak
--- a/src/Make_mvc.mak Thu Jun 25 18:36:26 2015 +0200
+++ b/src/Make_mvc.mak Fri Jun 26 01:26:10 2015 +0800
@@ -797,7 +797,7 @@
!endif
CFLAGS = $(CFLAGS) -DFEAT_MZSCHEME -I $(MZSCHEME)\include
!if EXIST("$(MZSCHEME)\collects\scheme\base.ss") \
- || EXIST("$(MZSCHEME)\collects\scheme\base.rkt")
+ || EXIST("$(MZSCHEME)\collects\racket\base.rkt")
# for MzScheme >= 4 we need to include byte code for basic Scheme stuff
MZSCHEME_EXTRA_DEP = mzscheme_base.c
CFLAGS = $(CFLAGS) -DINCLUDE_MZSCHEME_BASE
@@ -1170,7 +1170,7 @@
$(CC) $(CFLAGS) if_mzsch.c \
-DMZSCHEME_COLLECTS=\"$(MZSCHEME:\=\\)\\collects\"
mzscheme_base.c:
- $(MZSCHEME)\mzc --c-mods mzscheme_base.c ++lib scheme/base
+ $(MZSCHEME)\raco ctool --c-mods mzscheme_base.c ++lib scheme/base
$(OUTDIR)/if_python.obj: $(OUTDIR) if_python.c if_py_both.h $(INCL)
$(CC) $(CFLAGS) $(PYTHON_INC) if_python.c
diff -r a5e1a8813a3f src/if_mzsch.c
--- a/src/if_mzsch.c Thu Jun 25 18:36:26 2015 +0200
+++ b/src/if_mzsch.c Fri Jun 26 01:26:10 2015 +0800
@@ -871,7 +871,7 @@
mzscheme_main(int argc, char** argv)
{
#if MZSCHEME_VERSION_MAJOR >= 500 && defined(WIN32) && defined(USE_THREAD_LOCAL)
- scheme_register_tls_space(&tls_space, 0);
+ //scheme_register_tls_space(&tls_space, 0);
#endif
#ifdef TRAMPOLINED_MZVIM_STARTUP
return scheme_main_setup(TRUE, mzscheme_env_main, argc, argv);
diff -r a5e1a8813a3f src/os_win32.c
--- a/src/os_win32.c Thu Jun 25 18:36:26 2015 +0200
+++ b/src/os_win32.c Fri Jun 26 01:26:10 2015 +0800
@@ -435,7 +435,7 @@
#if defined(DYNAMIC_GETTEXT) || defined(PROTO)
# ifndef GETTEXT_DLL
-# define GETTEXT_DLL "libintl.dll"
+# define GETTEXT_DLL "intl.dll"
# endif
/* Dummy functions */
static char *null_libintl_gettext(const char *);
diff -r a5e1a8813a3f src/po/Make_mvc.mak
--- a/src/po/Make_mvc.mak Thu Jun 25 18:36:26 2015 +0200
+++ b/src/po/Make_mvc.mak Fri Jun 26 01:26:10 2015 +0800
@@ -63,7 +63,7 @@
PACKAGE = vim
# Correct the following line for the directory where gettext et al is installed
-GETTEXT_PATH = H:\gettext.0.14.4\bin
+GETTEXT_PATH = gettext-0.14.4\bin
MSGFMT = $(GETTEXT_PATH)\msgfmt
XGETTEXT = $(GETTEXT_PATH)\xgettext
diff -r 99fc18dc1ede src/main.c
--- a/src/main.c Sun Jun 28 19:24:40 2015 +0200
+++ b/src/main.c Wed Jul 01 15:46:58 2015 +0800
@@ -4014,9 +4014,9 @@
* endif
*/
ga_concat(&ga, (char_u *)":if !exists('+acd')||!&acd|if haslocaldir()|");
- ga_concat(&ga, (char_u *)"cd -|lcd -|elseif getcwd() ==# \"");
+ ga_concat(&ga, (char_u *)"cd -|lcd -|elseif getcwd() ==# \'");
ga_concat(&ga, cdp);
- ga_concat(&ga, (char_u *)"\"|cd -|endif|endif<CR>");
+ ga_concat(&ga, (char_u *)"\'|cd -|endif|endif<CR>");
vim_free(cdp);
if (sendReply)