很简单的一个插件,现在支持汉化Sublime Text2,Sublime Text3。全部系统Win64、Win32,Linux64,Linux32,OSX等,可以随意来回切换简体中文、繁体中文、日语、英语,无需重启SublimeText。
WordPress 数据结构分析
WordPress 数据结构分析
牛哥 发表于 11-22 12:32
WordPress仅仅用了10 个表:wp_comments, wp_links, wp_options, wp_postmeta, wp_posts, wp_term_relationships, wp_term_taxonomy, wp_terms, wp_usermeta, wp_users 按照功能大致分为五类 用户信息: wp_users和wp_usermeta 链接信息: wp_links 文章及评论信息: wp_posts、wp_postmeta、wp_comments 对分类,链接分类,标签管理: wp_term,wp_term_relationships,wp_term_taxonomy 全局设置信息: wp_options wp_posts 博客发表”文章”存放的地方就是这个wp_posts表了。这个表里存放的除了普通的文章之外,还有附件和页面(page)的一些信息。 post_type 字段是用来区分文章类型的。如果post_type是’post’,那么就是文章,如果是’page’,那么就是页面,如果是’attachment’, 那么就是附件了. wp_postmeta 这个表很简单,只有 meta_id, post_id, meta_key, meta_value 这四个字段。post_id 是相关 “文章” 的id。meta_value 是longtext类型的,这里仅是用来存储值。在撰写文章的时候,在编辑框下面有一个 Custom Fields 的选项,我们可以在这里添加post的meta信息。 wp_comments 比较重要的两个字段是 comment_post_ID 和 comment_approved,前一个用来指示这条评论隶属于哪一篇文章,后一个用来记录审核状况。还有一个比较有意思的是这个 commnet_agent 字段,可以利用这个字段来统计一下用户浏览器类型。 wp_users 用户帐号表。存储用户名、密码还有一些用户的基本信息。 wp_usermeta 类似上面的 wp_postmeta,存储一些其他的用户信息。 wp_options 用来记录Wordpress的一些设置和选项。里面有一个blog_id字段,这个应该是用在MU版里面来标示不同的 Blog 的。autoload这个字段用来控制是否选项总是被WordPress或者插件导入并缓存来使用,或者是否只是在要求的情况下才被导入。 wp_links 用来存储 Blogroll 里面的链接。 wp_terms 它保存(term)的基本信息。name 就是 term 的名字,slug 是用于使得 URL 友好化。term_group 是用于把相似的 terms 集合在一起。term_id 是term的唯一ID。 wp_term_taxonomy 分类信息,是对wp_terms中的信息的关系信息补充,有所属类型(category,link_category,tag),详细描述所拥有文章(链接)数量。 wp_term_relationships 把 posts和links这些对象和term_taxonomy表中的term_taxonomy_id联系起来的关系表,object_id是与不同的对 象关联,例如wp_posts中的ID(wp_links中的link_id)等,term_taxonomy_id就是关联 wp_term_taxonomy中的term_taxonomy_id。 WordPress使用MySQL数据库。作为一个开发者,我们有必要掌握WordPress数据库的基本构造,并在自己的插件或主题中使用他们。 截至WordPress3.0,WordPress一共有以下11个表。这里加上了默认的表前缀 wp_ 。 wp_commentmeta:存储评论的元数据 wp_comments:存储评论 wp_links:存储友情链接(Blogroll) wp_options:存储WordPress系统选项和插件、主题配置 wp_postmeta:存储文章(包括页面、上传文件、修订)的元数据 wp_posts:存储文章(包括页面、上传文件、修订) wp_terms:存储每个目录、标签 wp_term_relationships:存储每个文章、链接和对应分类的关系 wp_term_taxonomy:存储每个目录、标签所对应的分类 wp_usermeta:存储用户的元数据 wp_users:存储用户 在WordPress的数据库结构中,存储系统选项和插件配置的wp_options表是比较独立的结构,在后文中会提到,它采用了key-value模式存储,这样做的好处是易于拓展,各个插件都可以轻松地在这里存储自己的配置。 post,comment,user 则是三个基本表加上拓展表的组合。以wp_users为例,wp_users已经存储了每个用户会用到的基本信息,比如 login_name、display_name、 password、email等常用信息,但如果我们还要存储一些不常用的数据,最好的做法不是去在表后加上一列,去破坏默认的表结构,而是将数据存在 wp_usermeta中。wp_usermeta这个拓展表和wp_options表有类似的结构,我们可以在这里存储每个用户的QQ号码、手机号码、 登录WordPress后台的主题选项等等。 比较难以理解的是term,即wp_terms、wp_term_relationships、wp_term_taxonomy。在 WordPress的系统里,我们常见的分类有文章的分类、链接的分类,实际上还有TAG,它也是一种特殊的分类方式,我们甚至还可以创建自己的分类方 法。WordPress 将所有的分类及分类方法、对应结构都记录在这三个表中。wp_terms记录了每个分类的名字以及基本信息,如本站分为“WordPress开发”、 “WPCEO插件”等,这里的分类指广义上的分类,所以每个TAG也是一个“分类”。wp_term_taxonomy记录了每个分类所归属的分类方法, 如“WordPress开发”、“WPCEO插件”是文章分类(category),放置友情链接的“我的朋友”、“我的同事”分类属于友情链接分类 (link_category)。wp_term_relationships记录了每个文章(或链接)所对应的分类方法。 庆幸的是,关于term的使用,WordPress中相关函数的使用方法还是比较清晰明了,我们就没必要纠结于它的构造了。 在上文中我们已经介绍了WordPress数据库中各个表的作用,本文将继续介绍每个表中每个列的作用。WordPress官方文档已经有比较详细的表格,本文仅对常用数据进行介绍。 wp_commentmeta meta_id:自增唯一ID comment_id:对应评论ID meta_key:键名 meta_value:键值 wp_comments comment_ID:自增唯一ID comment_post_ID:对应文章ID comment_author:评论者 comment_author_email:评论者邮箱 comment_author_url:评论者网址 comment_author_IP:评论者IP comment_date:评论时间 comment_date_gmt:评论时间(GMT+0时间) comment_content:评论正文 comment_karma:未知 comment_approved:评论是否被批准 comment_agent:评论者的USER AGENT comment_type:评论类型(pingback/普通) comment_parent:父评论ID user_id:评论者用户ID(不一定存在) wp_links link_id:自增唯一ID link_url:链接URL link_name:链接标题 link_image:链接图片 link_target:链接打开方式 link_description:链接描述 link_visible:是否可见(Y/N) link_owner:添加者用户ID link_rating:评分等级 link_updated:未知 link_rel:XFN关系 link_notes:XFN注释 link_rss:链接RSS地址 wp_options option_id:自增唯一ID blog_id:博客ID,用于多用户博客,默认0 option_name:键名 option_value:键值 autoload:在WordPress载入时自动载入(yes/no) wp_postmeta meta_id:自增唯一ID post_id:对应文章ID meta_key:键名 meta_value:键值 wp_posts ID:自增唯一ID post_author:对应作者ID post_date:发布时间 post_date_gmt:发布时间(GMT+0时间) post_content:正文 post_title:标题 post_excerpt:摘录 post_status:文章状态(publish/auto-draft/inherit等) comment_status:评论状态(open/closed) ping_status:PING状态(open/closed) post_password:文章密码 post_name:文章缩略名 to_ping:未知 pinged:已经PING过的链接 post_modified:修改时间 post_modified_gmt:修改时间(GMT+0时间) post_content_filtered:未知 post_parent:父文章,主要用于PAGE guid:未知 menu_order:排序ID post_type:文章类型(post/page等) post_mime_type:MIME类型 comment_count:评论总数 wp_terms term_id:分类ID name:分类名 slug:缩略名 term_group:未知 wp_term_relationships object_id:对应文章ID/链接ID term_taxonomy_id:对应分类方法ID term_order:排序 wp_term_taxonomy
爱情公寓3爆笑揭幕秀 完整版
[youku id=”XMjg1MzUxODU2”]
神奇的图片
时间:2011-11-23 14:47
 【压力测试图】 1、如果看到波涛汹涌,那么请马上休假; 2、如果你看到微波荡漾,请小休几日; 3、如果看到很多颗榛子,请继续为人民币服务。
【压力测试图】 1、如果看到波涛汹涌,那么请马上休假; 2、如果你看到微波荡漾,请小休几日; 3、如果看到很多颗榛子,请继续为人民币服务。  动的越慢,心理承受力越好。
动的越慢,心理承受力越好。  【测试你潜在是天使还是魔鬼!】 如果你在图片上看到的魔鬼比天使还多,亲爱的,那你需要放松一下自己的心情,听听音乐,去郊外散散心,提升一下自己的正性能量,那会让你更健康。
【测试你潜在是天使还是魔鬼!】 如果你在图片上看到的魔鬼比天使还多,亲爱的,那你需要放松一下自己的心情,听听音乐,去郊外散散心,提升一下自己的正性能量,那会让你更健康。  【你喜欢哪张脸?】 选择左边的,你的喜好和广大男人们的喜好是一致的。 这两张脸都是合成的,左边一张是由8个小脚女人的脸合并而成;右边这个是8个大脚女人的脸合成的。通常,小脚女人有着更为漂亮的脸蛋。这一结论是纽约奥尔巴尼大学进化心理学家Jeremy Atkinson引导的实验中得出的。
【你喜欢哪张脸?】 选择左边的,你的喜好和广大男人们的喜好是一致的。 这两张脸都是合成的,左边一张是由8个小脚女人的脸合并而成;右边这个是8个大脚女人的脸合成的。通常,小脚女人有着更为漂亮的脸蛋。这一结论是纽约奥尔巴尼大学进化心理学家Jeremy Atkinson引导的实验中得出的。  【纯洁度测试】 你第一眼看到的是玫瑰还是…
【纯洁度测试】 你第一眼看到的是玫瑰还是…  【测试你的智力】 你能看道多少张脸呢? 1–3张:轻度弱智; 3–6张:正常人; 7–10张:超与常人; 11–15张:天才!
【测试你的智力】 你能看道多少张脸呢? 1–3张:轻度弱智; 3–6张:正常人; 7–10张:超与常人; 11–15张:天才!  【眼力大考验】 你能看到男人的脸吗? 3秒钟内找到:右脑神经发达,优于常人; 60秒内找到的:右脑神经正常; 1分钟到三分钟内找到的:右脑神经反应迟缓, 应该足量摄取肉类蛋白; 3分钟以上才找到的:右脑神经发育严重迟缓, 建议您多看卡通, 以帮助右脑正常发展。
【眼力大考验】 你能看到男人的脸吗? 3秒钟内找到:右脑神经发达,优于常人; 60秒内找到的:右脑神经正常; 1分钟到三分钟内找到的:右脑神经反应迟缓, 应该足量摄取肉类蛋白; 3分钟以上才找到的:右脑神经发育严重迟缓, 建议您多看卡通, 以帮助右脑正常发展。 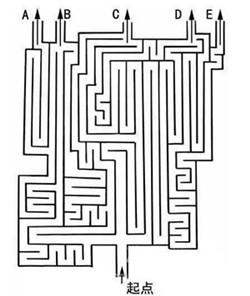 【走出迷宫,你适合什么职业?】 终点A的人适合职业:警察、教练、作家。 终点B的人适合职业:漫画家、会计、导演、设计师。 终点C的人适合职业:领导、律师、指挥。 终点D的人适合职业:医生、教师、歌手、记者、工人。
【走出迷宫,你适合什么职业?】 终点A的人适合职业:警察、教练、作家。 终点B的人适合职业:漫画家、会计、导演、设计师。 终点C的人适合职业:领导、律师、指挥。 终点D的人适合职业:医生、教师、歌手、记者、工人。  1到9格的图形,你最喜欢哪一个? 选好了吧!对对答案: 1代表你是个感性的人 2代表你很稳重 3代表你是个积极疯狂的人 4代表你是个十分普通的人 5代表你是个很自信的人 6代表你是个爱好和平的人 7代表是最好的,代表完美 8代表你是个很浪漫的人:) 9代表你是值得别人信任的人。
1到9格的图形,你最喜欢哪一个? 选好了吧!对对答案: 1代表你是个感性的人 2代表你很稳重 3代表你是个积极疯狂的人 4代表你是个十分普通的人 5代表你是个很自信的人 6代表你是个爱好和平的人 7代表是最好的,代表完美 8代表你是个很浪漫的人:) 9代表你是值得别人信任的人。  集中注意力,凝视画面中心的白色字母,神奇的事情就会发生……如果你看见粉色的爱心逐一被白色细线圈住,旋转起来,那就证明你心中充满了爱!
集中注意力,凝视画面中心的白色字母,神奇的事情就会发生……如果你看见粉色的爱心逐一被白色细线圈住,旋转起来,那就证明你心中充满了爱!
Comments
rexdf: 哈哈哈, :mrgreen: :roll:
这俩的relationship太复杂了!
[youku id=”XMjY3NjgxNDY4”]
Terrific决赛
Posted on 11月 12, 2006by dwyak
九、决赛
1. 决赛前
这是交大第一次欧洲参加比赛。之前虽然有一次荷兰的决赛,但那次交大没有能够进入决赛。欧洲,特别是布拉格这个城市,我们还是非常向往的。当然,出发之前lincx也嘱咐我们,“不要被异地的事物分散注意力”。我们努力去做了,毕竟我们的目标定得很高,自己也有压力。
一路上很不顺。在浦东机场换登机牌时,prof. yyu的签证出了问题,无法出境。原因是原先的签证日期错了,领馆又贴了一张新的签证,并且敲了一个”cancel”。问题是,这个”cancel”章敲错地方了,敲在了新贴的那张签证上了。于是,prof. yyu的签证实际上已经过期,他自然就无法出境了。在这种情况下,priest临时接过了领队的任务,带领大家去捷克。
上飞机前,roger的箱子因为体积过大,不能作为手提行李,被乘务员拖走了。结果,正因为是被乘务员拖走的,没走正常托运的途径。当我们在法国转机时,那个箱子一直拿不到。幸亏后来机场工作人员帮忙,我们才没有误掉下一班飞机。
东航十几小时的航行过程中,只给了一顿正餐、一顿早餐和两杯(还是三杯?)水。所以,当我们到达巴黎的时候,已经是又困又饿又渴了。巴黎飞往布拉格的飞机是架小飞机,只给一个羊角面包和一杯咖啡,不过总算还是吃了点东西……
到达布拉格的那天天气非常差,刮大风,还下冰雹。我们路上又冻到一下,身体状况都受了影响。所幸的是,队员都没有生病(priest病了)。
那天的另一个问题是,欧洲的插头和中国不同,需要转接器。我们不是没准备转接器,但是在prof. yyu那里,他没过来@_@
虽然很不顺,我们还是挺乐观,因为这叫攒rp——为World Champion攒着rp呢:) ——只是我们所有人都没有想到,我们是在为下一年的World Champion攒rp……
我们到达的第二天起,布拉格的天气变好了,一直到我们离开那天都很好。Prof. yyu也解决了签证问题,第二天赶了过来。而我们有了转接器,就能拼笔记本训练了。之后的几天,我们休息+旅游+训练,身体慢慢在恢复。不过,我还是感到两点不习惯的地方:
(1) 西餐吃不惯。在国内吃顿西餐,往往感觉还不错。但真到了西方,会发现这里的西餐味道和国内还是很不同的,可能这才是正宗的西餐吧。前两三顿还可以,吃到后来就受不了了。
(2) 时差问题。欧洲的时差和后来我去美国时感受到的时差完全两样。美国因为接近12小时时差,所以大不了把晚上睡觉时间缩短,增加午觉时间,不会很难受。欧洲的时差大约是1/4天,这样整个生活习惯都乱套了。该吃饭的时候没胃口,不该吃饭的时候很饿。睡觉也是一样,而且很难找到一个很好的快速倒时差的方法。
决赛前两三天,我们搬进了IBM提供的酒店。由于布拉格没有足够大的五星级酒店,所有队伍被分在了三个不同的酒店。我们在Renaissance(ms上海也有Renaissance)。IBM提供了两间房,我们三个队员一间,但是只是一个双人间。
同去决赛的潘书记(因为我们是下届主办方,所以派团去考察了)给我们出了个主意,把两张床拼起来睡。据说,他们一家三口出去都是这么睡的。但事实证明这个方案不好,至少睡在中间的我感觉睡不好。整个决赛期间,我睡得最好的一个晚上是决赛结束后的那个晚上。我郁闷地睡在了地上,结果那晚我睡得最好,比睡床上爽多了。
决赛期间的饭都是IBM、UPE招待的。不过,我发现一个问题,可以吃的菜很少。主要是,绝大多数菜我都不认识。我是要比赛的人,不敢乱吃东西,于是只能专门拿鸡腿吃@_@ 我终于理解为什么有传闻说清华一个队员在比赛前那天晚上吃了八根鸡腿了……
试机的那天,场面非常宏大。比赛场地是当地是市政大厅,据说以1块钱的价格租给了组委会。那是一个欧洲古典特色的大厅,墙壁上都是壁画,还有窗画。组委会还请来的交响乐团,当队员走入比赛场地时,乐团奏起了交响乐,非常有气势。后一年交大办比赛的时候效仿布拉格,请来了两届世界冠军的交大交响乐团为比赛演奏。
决赛的试机是永恒不变的那道题,并且可以从A到H交8遍。我们在试机时就跃跃欲试要抢个第一下来,Comars瞬间敲完后提交了8次,分别是run id 1~8。结果等了半天,返回了8个TLE。因为Comars读了屏幕……160分的罚时当然不可能拿第一了……
总的来说,直到决赛前一刻,我们都不顺。但我们认为这是在攒rp。不过,事实是,我们的不顺在比赛开始后仍在继续,而rp也仍然在攒……
其实,我们也没有那么天真。我们对于自己的目标并没有太大的把握,这是发自内心的。但是,表现在外面的是,我们装作很有自信的样子。决赛前那天晚上,tenshi躺在床上问我和Comars,“你们觉得我们队还有什么问题吗?”我心里一寒,我知道他心虚,我也心虚。不过早晨起床后,tenshi又说,“再过五六个小时就要捧杯了”。我们也表示赞同。
2. 决赛现场
决赛的第一个意外是,进场时Comars的可乐被收走了。从这一年的决赛开始,队员不准随意带资料进场了。资料被限制在25页,而且必须赛前上交组委会检查,并由组委会放在比赛的桌子上。原则上,进场时队员不能带任何东西。Comars带了一瓶可乐,按规则这是不允许的。换了别人,这可能只是一个小插曲。但对于Comars,可乐就是题目。
在Terrific队中,一般都是我做第一题的。但是比赛开始后,我读的C不能上去做。Comars读的F,明显是他的题。tenshi读的B,也比较难。于是,只好让Comars做第一题。 Comars做得还是挺快的,很快就有了一次提交,不过WA了。下来后,他喝了些矿泉水。因为没有可乐了,只能拿矿泉水代替。显然,矿泉水基本替代不了可乐。Comars查错进展得非常缓慢,一直都没有发现错误。
这时,我读出了H,是个求线段交点的题目。几何题一般都是tenshi做,我就交给了他。
tenshi去做H的时候。我发现E是可以做的,不过是日期题,必须小心。
tenshi的H做完后,交上去也是WA。
我去做E。我写得比较暴力,程序有点繁,不过核心部分应该不太容易错。可惜,输出的地方没注意,把两句话的顺序写反了。所以交上去也是WA。
在我做E的过程中,tenshi发现了H的错误。原因是他把线段求交点写成了直线求交点。改过后,H Y了。这时我们队Y的第一道题,90分钟时Y的。
UVa比赛
Posted on 08月 5, 2006by dwyak
第一次做UVa的比赛应该是高二的时候,那时网上比赛这个概念刚刚出来,我们也才知道,原来上网还能参加比赛。
那是2001年1月27日,UVa的第16场Online Contest(今天这场是第148场),题目是UVa Problemset的10080到10084。按照现在的水平,这5道题估计两小时内应该能做完了。这次比赛,我的成绩是0道。其实我写了3个程序,但是交上去都是Compile Error,并且不知道怎样才能改对。当时的UVa Pascal编译器是GNU Pascal (GPC),要求很怪。例如一定要加一个Program XXX(input, output),否则会Compile Error;再如,fillchar(a, sizeof(a), true)会Compile Error。总之,我一直不知道。于是之后的半年里,我在UVa比赛中的每次提交都是Compile Error。
后来,在和师兄WRS的共同努力下,我们终于克服的Compile Error的难关,开始在比赛中对题。而且,我们有时还能做出很高的排名,当然是作弊的(多台机器一起做,还用马甲)。
高三的时候,开始比较认真地接触ACM-ICPC,我才发现,要想不作弊地在UVa上取得一个好名次,还是有相当难度的。那时的UVa,有Meteors(02年总冠军), Saratov SU#3, Warsaw Eagles(03年总冠军),还有LML,强队挺多的。我是一个新手,还只有一个人,比赛开始后一两个小时就被别人(其实不是别人,就是LCX, LJ & ZJ)以2~3倍题数领先。那时的我居然还想在UVa比赛中拿第一——主要是因为水平相差太悬殊,以至于都不知道别人比自己强多少了。现在回想起来,当时的UVa比赛可以说是鼎盛时期,水平一点不亚于World Finals。
大一的时候,因为Meteors退役了,Saratov SU#3和Warsaw Eagles没来参加,我们在UVa比赛中还能取得不错的名次。我们主要的对手变成了ZJU。那年的ZJU正处在巅峰,而我们的实力尚未起来,所以我们在比赛中甚至处于下风。即便是在北京赛区,我们也有点害怕ZJU。我记得,这年,我们有过一次在UVa比赛中拿第一的经历(也是唯一的一次)。那次比赛好像才5道题,我们以微弱的时间优势赢了ZJU。
大一的寒假,因为没有进Final,我基本上都是单挑做比赛的。那段时间的单挑让我的实力长了不少。我想,主要原因是我基本的实力达到了,可以开始和其他队有竞争,再加上单挑的压力,成长速度特别快。这段时间,我单挑的成绩可以稳定地保持在前十了。我觉得,如果能稳定在前十,那么单挑UVa就会有很大的收获。否则,跟不上前面的队,那么单挑的价值就会降低。
大二的时候,我们的实力有了进一步的提高,在UVa上能经常拿拿第一了。当然,这和Saratov SU#3和Warsaw Eagles的退役也有很大关系。不过,我们赢的时候优势都很小。
回想起来,我们状态最好的时候应该是分区赛前后,那时连续几次都是第一。之后的比赛好像就变得困难起来了。KTH – Three Headed Monkey(04年决赛的亚军)来到了UVa比赛。在和他们的比赛中,我们完败。Final前的最后一次warm-up,KTH没来,我们侥幸赢了一场,结束了这个赛季的UVa系列比赛。
大三的时候,也就是Spirit这年,我们的队伍基本上成熟了。而且,这时的UVa比赛整体水平也严重下降。印象中,我不记得这一年我们在UVa上输过比赛了。有意思的是,10月初的一次warm-up,我们冒充Shahriar Manzoor(UVa的某老大)参加比赛。比赛到一半的时候,Shahriar Manzoor特地给了一个clarification,说“爬头的那支队不是我,但是他们很可能会成为你们比赛中的强劲对手:)”(原话不记得了,大致这个意思)。之后的那场比赛,为了避免误会,我们把“Shahriar Manzoor :-) ”改成了“)-: Rooznam Rairhahs ”。那场比赛,5个小时后,机房关门了,我们还剩最后一题没Y。Comars寝室要断电,就跑到我寝室来,在我室友的机器上完成了最后一题。之后,我陪他通了一宵。
这一年的UVa比赛,锻炼价值已经不大了,因为我们的优势很大,有时甚至能赢两题。我们发现,是时候去寻找一些更富挑战性的比赛去做了,例如SGU的比赛。之后,我们做UVa比赛的频率大大减小。Final前的最后一次warm-up,是我最后一次做UVa比赛。这一天,我们放弃了另一场很有意义的训练,来做UVa。不过,这时的UVa比赛确实大不如前了,这场比赛的收获也非常有限。
UVa的比赛,虽说到后期逐渐成为了鸡肋,但是就收获而言,它还是最大的。记得刚进交大的时候,LCX对我们说,他和LJ平时的训练是可能会偷偷懒,但是UVa的比赛一定会认真去做。因为这是一场比赛,有很多个对手,其中不乏强手,机会难得。虽然UVa的系统不怎么样,虽然题目可能出得不好,但是为了这些对手(或者我们可以把他们看作陪练),就冲着他们,我们也要重视这个比赛,投入全部的精力去做好UVa的比赛。
.
http://www.tudou.com/programs/view/zkHnEEfg9w0/
ORACLE CASE WHEN
ORACLE CASE WHEN 及 SELECT CASE WHEN的用法
分类: ORACLE SQL优化2009-08-12 14:10 6644人阅读 评论(0) 收藏 举报
CASE 语句
CASE selector WHEN value1 THEN action1; WHEN value2 THEN action2; WHEN value3 THEN action3; ….. ELSE actionN; END CASE;
CASE表达式
| DECLARE temp VARCHAR2(10); v_num number; BEGIN v_num := &i; temp := CASE v_num WHEN 0 THEN ‘Zero’ WHEN 1 THEN ‘One’ WHEN 2 THEN ‘Two’ ELSE NULL END; dbms_output.put_line(‘v_num = ‘ | temp); END; / |
CASE搜索语句
CASE WHEN (boolean_condition1) THEN action1; WHEN (boolean_condition2) THEN action2; WHEN (boolean_condition3) THEN action3; …… ELSE actionN; END CASE;
CASE搜索表达式
DECLARE a number := 20; b number := -40; tmp varchar2(50); BEGIN tmp := CASE WHEN (a>b) THEN ‘A is greater than B’ WHEN (a<b) THEN ‘A is less than B’ ELSE ‘A is equal to B’ END; dbms_output.put_line(tmp); END; /
SELECT CASE WHEN 的用法
select 与 case结合使用最大的好处有两点,一是在显示查询结果时可以灵活的组织格式,二是有效避免了多次对同一个表或几个表的访问。下面举个简单的例子来说明。例如表 students(id, name ,birthday, sex, grade),要求按每个年级统计男生和女生的数量各是多少,统计结果的表头为,年级,男生数量,女生数量。如果不用select case when,为了将男女数量并列显示,统计起来非常麻烦,先确定年级信息,再根据年级取男生数和女生数,而且很容易出错。用select case when写法如下: SELECT grade, COUNT (CASE WHEN sex = 1 THEN 1 /sex 1为男生,2位女生/ ELSE NULL END) 男生数, COUNT (CASE WHEN sex = 2 THEN 1 ELSE NULL END) 女生数 FROM students GROUP BY grade;
ORACLE中ESCAPE关键字用法 换字符用法
2007年07月01日 星期日 下午 09:16
ESCAPE用法
1.使用 ESCAPE 关键字定义转义符。在模式中,当转义符置于通配符之前时,该通配符就解释为普通字符。
2.ESCAPE ‘escape_character’
允许在字符串中搜索通配符而不是将其作为通配符使用。escape_character 是放在通配符前表示此特殊用途的字符。
select * from a WHERE name LIKE ‘%/%ab’ ESCAPE ‘/’
结果为:
name
-———
11%ab
12%ab
ESCAPE
Oracle Truncate Table 与 Delete Tabel的区别
一、
1.delete产生rollback,如果删除大数据量的表速度会很慢,同时会占用很多的rollback segments .truncate 是DDL操作,不产生rollback,速度快一些.
Truncate table does not generate rollback information and redo records so it is much faster than delete.
In default, it deallocates all space except the space allocated by MINEXTENTS unless you specify REUSE STORAGE clause.
2.不从tablespace中腾出空间,需要
ALTER TABLESPACE AAA COALESCE; 才有空间
3.truncate 调整high water mark 而delete不.truncate之后,TABLE的HWM退回到 INITIAL和NEXT的位置(默认)
delete 则不可以。
4.truncate 只能对TABLE
delete 可以是table,view,synonym
5.TRUNCATE TABLE 的对象必须是本模式下的,或者有drop any table的权限 而 DELETE 则是对象必须是本模式下的,或被授予 DELETE ON SCHEMA.TABLE 或DELETE ANY TABLE的权限
二、 truncate是DDL語言.
delete是DML語言
DDL語言是自動提交的.
命令完成就不可回滾.
truncate的速度也比delete要快得多.
三、 truncate 会把 highwatermark 回归至 0 … 当下一次再插入新资料时就会快一些啦。
所以一般都是在 temp table 上使用的,不过要注意就是 truncate 不能在 pl/sql 上使用,要用 dynamic SQL 才可以。
四、
当你不再需要该表时, 用 drop;
当你仍要保留该表,但要删除所有记录时, 用 truncate;
当你要删除部分记录时(always with a WHERE clause), 用 delete.
五、