很简单的一个插件,现在支持汉化Sublime Text2,Sublime Text3。全部系统Win64、Win32,Linux64,Linux32,OSX等,可以随意来回切换简体中文、繁体中文、日语、英语,无需重启SublimeText。
小玩Acdream_OJ
密码被盗事件后果
目前社交网站这么多,一般我们没有办法记住这么多密码的。而且很多网站强行要求注册才可以查看或者下载,往往临时申请一个,然后就忘记了,下次使用再次申请。对于要求比较烦人的比如pudn,一般来说我都是直接不会点开的,或者发动百度百科、百度贴吧的力量来下载,总之这样的网站我为之不齿。
然后账号一多,往往对于普通网站,无意中就形成了一个通用密码的习惯。这样就埋下了深深的危机。
GCC 4.8.2在Cygwin上的一些问题
Arch Linux杂记
Archlinux安装笔记。
figlet中文支持–Cygwin实现
figlet可以用来画ASCII的字符,很是有趣。
____ _ __
| _ \ _____ ____| |/ _|
| |_) / _ \ \/ / _` | |_
| _ < __/> < (_| | _|
|_| \_\___/_/\_\__,_|_|
GnuPG使用笔记
一点关于gnupg的使用笔记。
OpenMP在win上面的编译
并行库有有Intel® Threading Building Blocks和微软的Parallel Patterns Library,开源的OpenMP等。 架构有Google的Sawzall,Yahoo的Pig 猪和微软的Dryad。 MPI消息机制
而在异构多核计算中,有Nvdia的CUDA™,即Compute Unified Device Architecture;而微软虽然有了DirectX也不甘示弱,提出了C++ AMP (C++ Accelerated Massive Parallelism),以利用显卡日益增加的大规模浮点运算能力。而开源的则对应于OpenCL。
总的来说前前面的几种都是利用多线程在CPU上加速,主要的就是解决线程同步互斥,CPU的Cache冲突等;而后面的则是解决显卡硬件的通用浮点计算。现在显卡的计算性能已近比CPU高出了好几个数量级了,这么高的计算性能,主要是由于大型视屏游戏发展带来的,因此主要都是针对DirectX和OpenGL做的驱动,解决图形运算。然而这么强大的运算能力,自然就想在其他方面利用起来,因此CUDA和C++AMP,OpenCL,WebCL等出现了。简单点说就是在显卡上另外设计一个驱动和行业API适应通用大规模数值运算需求。用途有比如已经不能用了的比特币挖矿,密码破解等。
下面主要记录一下一次编译的经历:
#include <iostream>
#include <time.h>
void test()
{
int a = 0;
for (int i=0;i<100000000;i++)
a++;
}
int main()
{
clock_t t1 = clock();
for (int i=0;i<8;i++)
test();
clock_t t2 = clock();
std::cout<<"time: "<<t2-t1<<std::endl;
}
另一段代码
#include <iostream>
#include <time.h>
void test()
{
int a = 0;
for (int i=0;i<100000000;i++)
a++;
}
int main()
{
clock_t t1 = clock();
#pragma omp parallel for
for (int i=0;i<8;i++)
test();
clock_t t2 = clock();
std::cout<<"time: "<<t2-t1<<std::endl;
}
在cygwin的g++4.8.2下面编译,得到如下结果:

而如果使用VS2013编译,第二个代码工程在C/C++ –> Language –> Open MP Support yes(/openmp)

而我使用Dev-cpp5.6.1里面的MingW G++ 4.8.1编译结果则是比vs结果略微差一点:

这里比较奇葩的就是cygwin的生成的了,看了有必要分析下生成的代码了。如此的奇葩。
Cygwin安装nokogiri
前言
本来是打算写一个抓取图片的脚本,然而自然需要Parse HTML了,C语言有谷歌大名鼎鼎的gumbo-parser,Python自然有妇孺皆知的Beautiful Soup,而Java实现则是较多功能完善,Perl语言有HTML::Parser等等不一而足。而且仅仅抓取图片,往往有现成的脚本或者专门针对特定网站的浏览器助手Chrome Plugins或者Firefox Plugins。然而由于最近对于Python和Perl有些腻了,想玩玩Ruby,实际上我已经借助Firefox的DownloadThemALL下载完成了图片了。
ruby环境
在win下面越来越喜欢cygwin了,一方面自然是因为cygwin的更新频率了,基本上和Ubuntu一样,每过了一周左右,更新就会发现有软件升级了,这样自然就是软件的错误越来越少。 其次我还是比较喜欢Linux的bash的,循环相对cmd来说要强很多。 因为有了cygwin,那么Perl和Ruby这两个基本不需要另外安装了,运行大部分的软件,安装CPAN和Gems都还很方便,当然这里还是需要一定的技巧的。不过Python和Java则最好是另外安装,而且把他们放到cygwin/bin/的%PATH%环境变量前面,这样的话,Cygwin运行的时候Cygwin的Python和Java自动重新配置$PATH就不会与Win的发生干扰了。
编译安装
我尝试着直接使用gem instal nokogiri安装,自然是提示错误了,当时具体什么错误则说的不够详细,自然也就不知道怎么path了。
1. 下载源码
git clone https://github.com/sparklemotion/nokogiri,git
2. 安装Libxml2和Libxsl依赖
首先关闭cygwin打开setup.exe,搜索libxml2和libxsl,把lib装上,我是把Python下面的也装了的,理论上应该不需要Python下面的。
3. 安装racc
这个比较简单,直接gem install racc,即可。 检验便是敲入racc,会提示no input而不是找不到命令
4. 安装rex
这个比较难,首先直接运行gem install rex,会提示一个错误,但是安装完成是OK的。 接着输入rex会提示如下的错误
$ rex
/usr/lib/ruby/gems/1.9.1/gems/rex-1.0.2/lib/rex/rexcmd.rb:66:in `initialize': undefined method `collect' for #<String:0x80195bd8> (NoMethodError)
from /usr/lib/ruby/gems/1.9.1/gems/rex-1.0.2/bin/rex:18:in `new'
from /usr/lib/ruby/gems/1.9.1/gems/rex-1.0.2/bin/rex:18:in `<top (required)>'
from /usr/bin/rex:23:in `load'
from /usr/bin/rex:23:in `<main>'
我们打开定位到/usr/lib/ruby/gems/1.9.1/gems/rex-1.0.2/lib/rex/rexcmd.rb,会发现
class Cmd
OPTIONS = <<-EOT
o -o --output-file <outfile> file name of output [<filename>.rb]
o -s --stub - append stub code for debug
o -i --ignorecase - ignore char case
o -C --check-only - syntax check only
o - --independent - independent mode
o -d --debug - print debug information
o -h --help - print this message and quit
o - --version - print version and quit
o - --copyright - print copyright and quit
EOT
....
def initialize
@status = 2
@cmd = File.basename($0, ".rb")
tmp = OPTIONS.collect do |line|
...
def usage( msg=nil )
f = $stderr
f.puts "#{@cmd}: #{msg}" if msg
f.print <<-EOT
Usage: #{@cmd} [options] <grammar file>
Options:
EOT
OPTIONS.each do |line|
根据运行rex提示的错误就是OPTIONS.collect这里才错误了,很明显嘛,OPTIONS是一个string,查一下就发现问题的关键了,ruby的1.9以后 Ruby 1.9: String is no longer Enumerable. …Can't call collect directly; we have to split it into lines first. 所以,String是没有collect方法的了,String不是可枚举的。知道原因就好pach了。直接改成OPTIONS.split(/\n/).each do |line| 和tmp = OPTIONS.split(/\n/).collect do |line|即可。然后再次运行rex则正常的提示了:
$ rex
rex: no grammar file given
Usage: rex [options] <grammar file>
Options:
-o,--output-file <outfile> file name of output [<filename>.rb]
-s,--stub append stub code for debug
-i,--ignorecase ignore char case
-C,--check-only syntax check only
--independent independent mode
-d,--debug print debug information
-h,--help print this message and quit
--version print version and quit
--copyright print copyright and quit
5. 安装
cd nokogiri
rake
然后等待就好。
坑爹的hdu3265
起源于在做这道经典的扫描线的题目的时候,采用了按照我的思维倾向,横轴优先,那么就用竖轴做线段树,思路很简单。这里有两种划分的方法
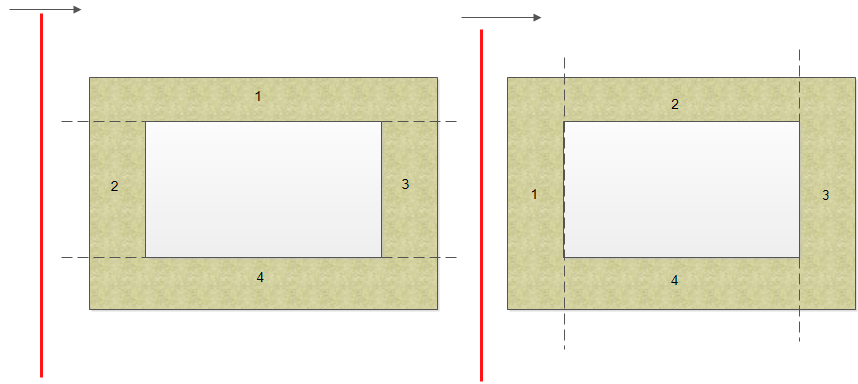 问题出在,从左向右的用扫描线的时候,按照左图的方式是是无限的Stack_Overflow的,而我本地测试了多组10000+的随机最大范围数据,对拍均是正常的。 至今任然想不明白是否是我线段树实现的问题,还是题目stack限制的问题。理论上区区线段树不可能出现stack_overflow的啊!!求大神解释
问题出在,从左向右的用扫描线的时候,按照左图的方式是是无限的Stack_Overflow的,而我本地测试了多组10000+的随机最大范围数据,对拍均是正常的。 至今任然想不明白是否是我线段树实现的问题,还是题目stack限制的问题。理论上区区线段树不可能出现stack_overflow的啊!!求大神解释
|
线段树起始下标0还是1
线段树可以写成结构体的形式,专门用一个元素left和right来存储,这样的写法基本上属于学院派,一些非ACMer会这么写,而理解性上个人觉得并没有什么本质的提升。 作为ACMer的基础中的基础的数据结构,线段树写法一般是开一个4N的数组,用来存储线段树的各个节点。
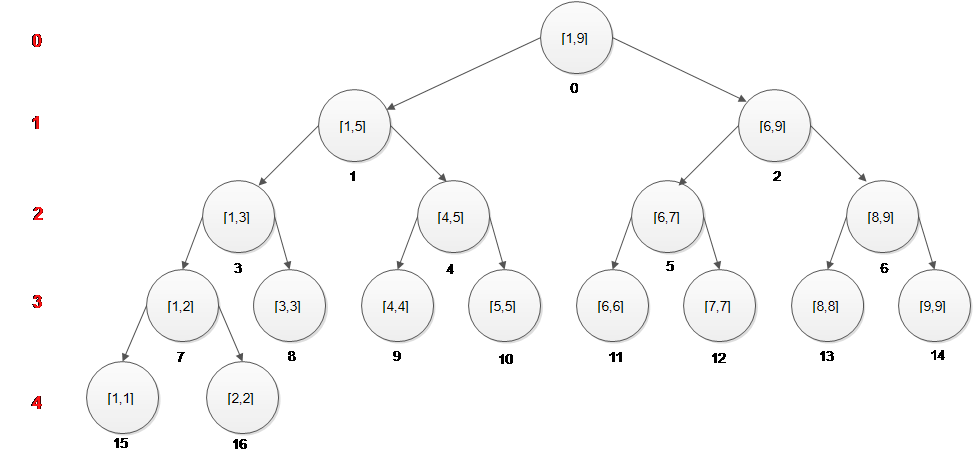
线段树的节点:[1,N],[1,N/2],[N/2+1,N],… 假如N=9,则存在17个节点:[1,9] [1,5] [6,9] [1,3] [4,5] [6,7] [8,9] [1,2] [3,3] [4,4] [5,5] [6,6] [7,7] [8,8] [9,9] [1,1] [2,2] 可以容易发现线段树是一颗完全树。
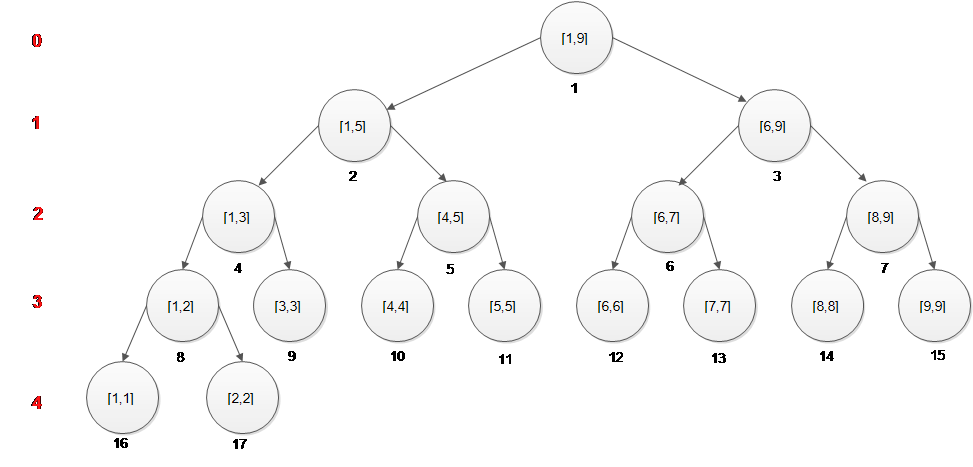 节点在数组中的编码方案(采用从1开始数组)是: 0层[1,N] 1层[1,N/2]、[N/2+1,N] 2层[1,N/2/2]、[N/2/2+1,N/2]、[N/2+1,(N+N/2+1)/2]、[(N+N/2+1)/2+1,N] … 容易发现正如完全树的定义一样,除了最后一层,第i层有2^i个节点。 [1 2 4 8 …] 所以如果加上一个1的话,就可以构成了二次幂的坐标了 [1 1 2 4 8…] 加入开始那个1为-1层,那么我们就可以说到第i(i>=0)层,第一个节点的坐标是2^i。
节点在数组中的编码方案(采用从1开始数组)是: 0层[1,N] 1层[1,N/2]、[N/2+1,N] 2层[1,N/2/2]、[N/2/2+1,N/2]、[N/2+1,(N+N/2+1)/2]、[(N+N/2+1)/2+1,N] … 容易发现正如完全树的定义一样,除了最后一层,第i层有2^i个节点。 [1 2 4 8 …] 所以如果加上一个1的话,就可以构成了二次幂的坐标了 [1 1 2 4 8…] 加入开始那个1为-1层,那么我们就可以说到第i(i>=0)层,第一个节点的坐标是2^i。
 可以试着自己画的一试就知道了,如果第一个节点放到0节点,那么会发现2^i出现的地方是每层的第二个节点,这样便形成了一种数学形式上的复杂,同时也会增大代码的复杂度。
可以试着自己画的一试就知道了,如果第一个节点放到0节点,那么会发现2^i出现的地方是每层的第二个节点,这样便形成了一种数学形式上的复杂,同时也会增大代码的复杂度。